When Plan Mode Was No Longer Enough
Plan Mode initially felt like enough
My workflow with Codex CLI used to be relatively simple.
I would enter Plan Mode, discuss what I wanted to implement, refine the scope, question some decisions, and eventually reach a plan that looked reasonable.
Then I would leave Plan Mode and ask Codex to execute it.
For a while, this felt like a good separation of responsibilities. First, we would think. Then, the agent would implement.
But eventually, it stopped being enough.
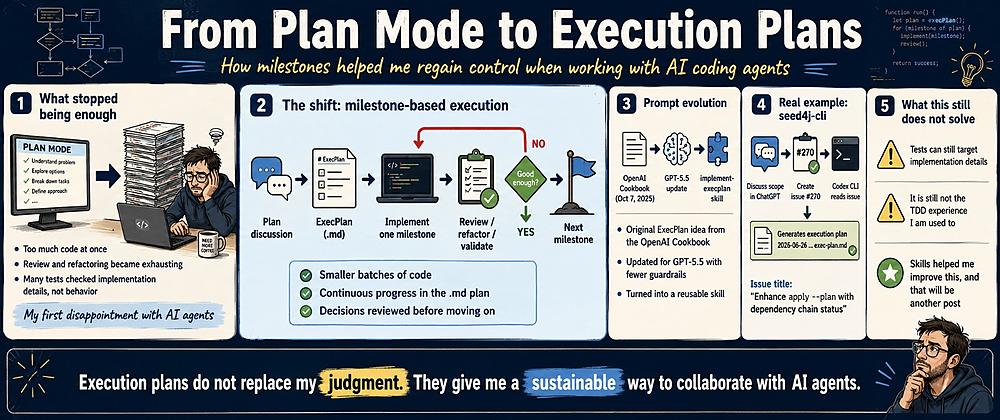
My first disappointment with AI agents
The problem was not that Codex could not generate the code.
The problem was that it could generate too much code at once.
After a large implementation, I would receive a substantial set of changes that I still needed to understand, review, refactor, and validate. Sometimes the implementation was technically correct, but it contained decisions I would not have made myself.
Other times, the tests passed, but some of them were tied to implementation details instead of protecting actual behavior.
I started to feel exhausted after these sessions.
The agent had accelerated implementation, but it had also created a large review queue for me. I was no longer spending most of my energy writing code. I was spending it trying to absorb, validate, and reshape everything the agent had produced.
The bottleneck had moved.
Codex was not struggling to generate code. I was struggling to review that code responsibly.
This was my first real disappointment with AI agents.
Not because they were incapable, but because I realized that generating code faster does not automatically make the entire development process faster.
Shrinking the feedback loop
While searching for a better approach, I found the OpenAI Cookbook article Using PLANS.md for multi-hour problem solving.
It describes an execution plan, or ExecPlan, as a self-contained and continuously updated document that an agent can follow while implementing a complex change.
An ExecPlan is more than a list of tasks.
It includes the purpose of the change, the current context, the desired behavior, implementation milestones, validation commands, risks, decisions, progress, and lessons learned.
The concept that made the biggest difference for me was dividing the implementation into milestones.
Instead of asking Codex to execute the entire plan, I started asking it to implement one milestone at a time.
After each milestone, I could:
- review a smaller volume of code;
- refactor while the context was still manageable;
- verify whether the tests protected behavior;
- question design decisions;
- run focused validation;
- update the plan with what we had learned;
- decide whether the implementation was ready to continue.
Only after I considered the result good enough would I ask Codex to implement the next milestone.
The milestone became the unit of collaboration between me and the agent.
Turning the idea into a skill
The OpenAI Cookbook article is dated October 7, 2025, and its current version recommends gpt-5.2-codex.
After GPT-5.5 was released, I asked the model to revise the original instructions and make them more appropriate for the newer model.
The result required fewer step-by-step directions and placed more emphasis on the properties the final execution plan should preserve.
I then transformed those instructions into my implement-execplan skill.
The skill defines an ExecPlan as a living document. It requires the agent to maintain sections such as:
- purpose and scope;
- existing context;
- desired end state;
- implementation milestones;
- progress;
- decisions and their rationale;
- risks and mitigations;
- validation strategy;
- lessons learned.
It also requires each milestone to contain concrete changes, validation commands, and observable acceptance criteria.
However, the most important part of my workflow does not come only from the structure of the document.
It comes from controlling when the next milestone starts.
I do not want the agent to finish faster than I can understand the change.
A real example in seed4j-cli
A concrete example came from a feature I implemented in seed4j-cli.
The ChatGPT Android app allows me to use a GitHub integration that can read repositories. I used it to inspect the project and discuss the feature with GPT-5.5 in an experience similar to Codex CLI Plan Mode.
After refining the scope, I created the issue Enhance apply --plan with dependency chain status.
The goal was to improve the output of:
seed4j apply <module> --project-path . --plan
The command already displayed resolved parameters, but it did not explain whether the module dependencies had already been applied, were still pending, or required an explicit feature choice.
When it was time to implement the feature, I asked Codex CLI to read the issue and use my skill to create this execution plan:
2026-06-26_FEATURE_apply-plan-dependency-status-exec-plan.md
The work was divided into four milestones:
- establish the living execution plan;
- add the status of direct module dependencies;
- add feature dependency satisfaction and pending choices;
- update documentation and validate formatting.
This division gave me natural stopping points.
After the direct module dependency behavior was implemented, I could review it before introducing the more complex feature dependency rules.
After the behavior was stable, documentation and formatting could be handled separately.
What changed was not necessarily the quality of every generated line.
What changed was the size of the feedback loop.
The document became part of the work
There was another benefit I had not fully anticipated.
The execution plan became a record of the implementation.
During the work, Codex continuously updated the document with completed milestones, design decisions, validation results, discovered risks, unrelated repository problems, and lessons learned.
For example, the final document records why dependency planning remained in the CLI primary adapter, why CLI integration tests were used as the behavior contract, and why the dependency traversal needed to be deterministic and cycle-safe.
It also records that the repository-wide formatting check contained pre-existing failures unrelated to the feature, while the files changed by the implementation passed focused formatting validation.
Without the execution plan, much of that context would have disappeared inside the conversation.
The code would remain, but the reasoning behind several decisions would be lost.
Instead, I ended the implementation with both working code and a document describing how the implementation evolved.
In another post, I plan to explain what I started doing with these files instead of simply discarding them after the feature was completed.
What this approach still does not solve
Execution plans helped me control the size of generated changes, but they did not solve everything.
Codex can still create tests that are too closely tied to implementation details. A smaller milestone makes those tests easier to identify, but it does not automatically make them good.
This approach also does not reproduce the TDD experience I was used to.
In traditional TDD, the feedback loop begins with a failing test that expresses the next behavior. The design emerges through small cycles of failure, implementation, and refactoring.
An ExecPlan organizes implementation into milestones, but a milestone can still contain too much production code before the right behavioral tests are established.
I have made progress in this area by combining execution plans with other skills and more explicit testing workflows.
That deserves its own post because it changes not only how the agent implements a feature, but also how I participate during the implementation.
Regaining control without rejecting the agent
My first reaction to the review burden could have been to reduce my use of AI agents.
Instead, I changed the granularity of the work I delegated to them.
The answer was not a more detailed initial conversation followed by an even larger autonomous implementation.
The answer was a living plan, smaller milestones, explicit validation, and deliberate stopping points.
I still review the code.
I still refactor it.
I still question tests and design decisions.
The execution plan does not remove my responsibility from the process. It gives me a structure that makes that responsibility sustainable.
For me, that has become one of the most important lessons about working with coding agents:
The agent’s ability to generate code is not the only limit that matters.
My ability to understand, validate, and improve that code matters just as much.